データベースの構築データのデジタル化が完了すると、それをデータベースとして整備する作業に入ります。データ入力時点でデータベースの主要な構造はでき上がっていますが、入力された各データの標準化の作業が残されています。特に、一般の研究者に親しまれているファイルメーカーは、使いやすい一方で項目の設定が曖昧になりがちで、項目内のデータ形態も自由度が高い反面、不ぞろいのデータになりがちです。データベースとしての完成度を上げるためには、入力データに基づいて、構造の再検討と入力データの修正が必要です。
|

データベースの構築データのデジタル化が完了すると、それをデータベースとして整備する作業に入ります。データ入力時点でデータベースの主要な構造はでき上がっていますが、入力された各データの標準化の作業が残されています。特に、一般の研究者に親しまれているファイルメーカーは、使いやすい一方で項目の設定が曖昧になりがちで、項目内のデータ形態も自由度が高い反面、不ぞろいのデータになりがちです。データベースとしての完成度を上げるためには、入力データに基づいて、構造の再検討と入力データの修正が必要です。
|
著作:牧野シーボルト標本データベース作製グループ 2004年
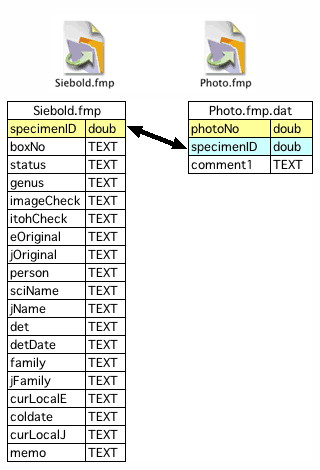 項目設定とリレーションの設定(入力用データベース)
項目設定とリレーションの設定(入力用データベース) 長過ぎるデータの処理
長過ぎるデータの処理